매번 말하는 것 같긴한데 저는 가상화 기술이 너무 좋아요!
자연스럽게 CNCF 재단 쪽 프로젝트는 이름만 들어도 설레는 지경에 이르렀다...
CNCF 계열 프로젝트 중 Observability쪽인 Prometheus랑 Grafana에 대해 알아보게 되었다
Prometheus
무려 SoundCloud에서 만든 오픈소스 시스템 모니터링 및 경고 툴킷이다
Prometheus는 한 마디로 설명하자면 시계열 데이터베이스 특화형 모니터링 도구이다
시계열 데이터베이스가 뭔데?
- 말 그대로 시간에 따라 저장된 데이터
- 시간을 중심으로 측정되는 데이터이므로 시간에 따른 변화를 측정하기 좋음
- backend의 영역에서는 모니터링의 역할
- IoT, 센서 데이터 / 금융 데이터(주식) 에서 자주 사용
Cloud Native한 모니터링 도구라는 게 큰 강점이다
CNCF 계열 프로젝트들은 대부분은 백엔드에 Prometheus를 지원하기 때문에 CNCF 프로젝트들과 통합성이 좋다
- 예시로, 쿠버네티스나 도커 엔진은 Container & Node의 Metrics를 내보내는 Endpoint인 /metrics (또는 /metrics/cAdvisor) 를 자체적으로 내장
Prometheus의 아키텍쳐
Metrics
아키텍쳐에 대해 알아보기 앞서 Metircs를 내보내고 수집한다는 표현을 썼는데,
그렇다면 Metrics는 어떤 정보를 포함하고 있는 걸까?
주로 아래와 같은 정보들을 Metrics는 포함하고 있다.
| 구분 | 세부사항 |
| 서비스 코드 | 총 http 요청 수, 요청 처리 시간 |
| 인프라 / 시스템 | CPU 사용 시간, 사용 중인 메모리 |
이에 더불어서 K8S, Docker, LB 단에서도 수집 가능한 메트릭을 제공한다.
K8S 같은 경우 각 Pod, Docker 컨테이너 단위에서 CPU, 메모리 리소스 사용량을 수집해서 Health Check를 할 수 있다.
그치만 무엇보다 중요한 건
수집하고자 하는 메트릭을 선정하는 것은 내가 “어디서” “어떤 장애”를 관찰하고 싶은지에 따라 달라짐(사바사라는 뜻)
이 부분은 모니터링 방법론에 대해 다루면서 따로 포스팅해볼게요.

또 아주 좋은 그림을 가져왔다
Prometheus는 위처럼 pulling 방식으로 Target System에서 exporter를 통해 메트릭을 수집해온다
- pulling : prometheus server가 Target System에서 메트릭을 요청해서 받아오는 방식
- 반대인 push는 Target System이 메트릭을 내보내는 방식이다.
- 예전에 Wazuh라는 오픈소스를 써봤는데 그게 이 방식
Prometheus 로컬에서 써보기
https://prometheus.io/download/
Download | Prometheus
Downloads for the latest releases of the Prometheus monitoring system and its major ecosystem components.
prometheus.io
내 OS에 맞는 prometheus를 다운받고 압축해제 해줬다.
킹영한의 강의를 들으면서 쓰고 있는 Spring Boot 프로젝트를 모니터링 대상으로 추가해보겠다.
intelliJ로 프로젝트 빌드하는 게 빨라서 그렇게 설정해뒀는데, prometheus 의존성 추가해주려고 Gradle로 빌드하는 방식으로 변경해줬다.
build.gradle 경로에 다음과 같은 의존성 주입
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'
prometheus.yml 파일에는 다음과 같은 job을 추가해줬음
- job_name: "spring"
metrics_path: '/actuator/prometheus'
scrape_interval: 1s
static_configs:
- targets: [ 'localhost:8080' ]
localhost:9090으로 접속하면 up으로 뜸
트러블 슈팅 : kata-container와 prometheus 연동
사실 내가 이 지경까지 오게된 이유는 이전 포스팅으로 올렸던 kata-container 때문이다.
kata 설치 및 ctr 명령어로 VM 생성까지는 어떤 어려움도 없었는데, prometheus 연동을 시작하면서 문제가 생겼다.
kata는 K8S의 cAdvisor처럼 각 VM별 메트릭을 prometheus로 메트릭을 내보낼 수 있다.
kata metric 수집 아키텍쳐

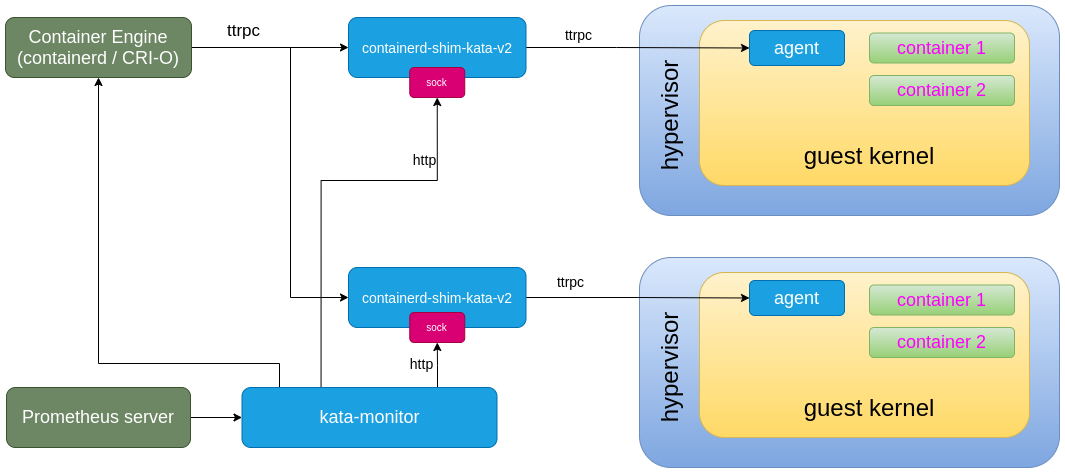
- kata- agent
- 각각의 kata container를 생성할 때마다 안에 생기는 친구(= K8S cAdvisor)
- 밑에서 말할 kata-monitor에 메트릭을 전달해주는 역할
- kata-monitor
- kata VM 밖에서 Host OS 레벨에서 실행되는 친구
- prometheus가 읽어갈 수 있도록 정리해줌
- 중계 / scraper 역할
- prometheus exporter
- kata-monitor랑 함께 Host OS 레벨에서 실행됨
- HTTP 엔드포인트로 노출시켜서 Prometheus로 전달
이론상 kata-monitor를 활성화 시키면 메트릭 수집이 되야하는데..

위 사진처럼 kata-monitor는 활성화 되는데 rpc error가 자꾸 발생해서 실제 메트릭 수집이 안 된다.
실제로 소켓이 활성화 되지 않는 듯하다.. 이거 때문에 gRPC부터 시작해서 실제로 kata-agent와 kata-monitor가 통신할 때 사용하는 경량화된 gRPC인 ttrpc까지 찾아봤다..
혹시 이 세계에 이 문제를 함께 해결해줄 분이 계시다면 댓글을 남겨주세요.